[Java] 크롤링, Jsoup과 Selenium 중 어떤 도구를 선택해야할까?
웹 크롤링은 인터넷에 흩어진 정보를 자동으로 수집하고 분석하는 데 매우 유용한 기술입니다. 가격 비교, 뉴스 수집, 데이터 정제, 트렌드 분석 등 다양한 분야에서 활용되며, 반복적인 수작업을 자동화할 수 있다는 장점이 있습니다.
Java 환경에서 웹 크롤링을 구현할 때 가장 많이 사용되는 Jsoup과 Selenium 두 가지 도구가 존재합니다. 이 두 도구는 목적과 특성에 따라 분명한 차이를 가지고 있어, 상황에 맞는 선택이 중요합니다.
이번 포스팅에서는 Jsoup, Selenium의 특징, 실제 크롤링을 수행하는 예제를 통해 어떤 방식으로 동작하는지, 각 도구의 차이점에 대해 알아보도록 하겠습니다.
SSR과 CSR의 개념
Jsoup과 Selenium의 차이를 이해하기에 앞서, 웹 사이트가 데이터를 사용자에게 어떻게 렌더링 하는지에 대한 개념을 먼저 이해하는 것을 추천드립니다. 즉, 해당 페이지가 `서버 사이드 렌더링(SSR)`인지, `클라이언트 사이드 렌더링(CSR)`인지 아는 것이 도구 선택에 직접적인 영향을 줍니다.
SSR과 CSR의 차이에 대한 설명은 아래 참고 글을 통해 확인해 보시기 바랍니다.
CSR과 SSR의 개념과 차이점 (feat. SPA, MPA)
CSR과 SSR의 개념과 차이점을 알아보기 전 SPA와 MPA의 개념과 차이점에 대해 먼저 알아보도록 하겠습니다. SPA(Single Page Application) 개념한 개(Single)의 Page로 구성된 ApplicationCSR(Client Side Rendering) 방식
tao-tech.tistory.com
Jsoup 이란?
Jsoup은 Java로 작성된 HTML 파서로, 웹 페이지의 HTML 문서를 가져와 파싱 하고, 원하는 요소를 선택하여 데이터를 추출할 수 있도록 도와주는 라이브러리입니다.
HTML 문서를 객체화하여 DOM 트리로 접근할 수 있게 해 주며, 마치 jQuery에서 사용하는 CSS 선택자 문법을 그대로 사용할 수 있어서 사용법이 매우 직관적입니다.
Jsoup의 특징
- `정적 페이지에 최적화` Jsoup은 서버에서 미리 렌더링 되어 클라이언트로 전달되는 HTML을 처리하는데 특화되어 있습니다. 반대로, JavaScript로 동적으로 생성되는 콘텐츠는 Jsoup 단독으로는 접근할 수 없습니다.
- `빠르고 가벼운 사용성` 브라우저나 WebDriver를 실행하지 않고, 단순히 HTTP 요청과 응답만 처리하기 때문에 리소스 소모가 매우 적고 속도도 빠릅니다.
- `CSS 선택자 기반의 편리한 요소 탐색` jQuery나 Selenium과 마찬가지로, `div.title`, `ul > li`, `a[href]` 같은 CSS 선택자 문법으로 HTML 요소를 쉽게 추출할 수 있습니다.
- `설정이 간단하고 의존성이 적다` WebDriver나 브라우저 설치 없이, Maven 또는 Gradle에 간단히 의존성만 추가하면 바로 사용할 수 있어 개발 초기 설정이 간편합니다.
Jsoup 사용 예제
Jsoup 크롤링 예제로 필자 블로그 글 목록을 불러오는 코드를 통해 알아보도록 하겠습니다.
먼저, Jsoup을 사용하기 위한 의존성을 추가합니다.
1. 의존성 추가
implementation 'org.jsoup:jsoup:1.21.1'Jsoup 다운로드, 의존성 추가에 대해서 아래 사이트를 통해 참고 바랍니다.
Download and install jsoup
Download and install jsoup jsoup is available as a downloadable .jar java library. The current release version is 1.21.1. What's new See the 1.21.1 release announcement for the latest changes, or the changelog for the full history. Previous releases of jso
jsoup.org
2. Jsoup 크롤링 첫 번째 : Document 생성
예제에서 크롤링하려는 데이터는 게시글 제목과 이동할 url입니다. 먼저 해당 사이트의 url을 가져와 Document를 생성합니다.
@Slf4j
@Service
public class JsoupCrawler {
private static final String URL = "https://tao-tech.tistory.com";
public void process() {
Document document = null;
try {
document = Jsoup.connect(URL)
.userAgent("Mozilla/5.0") // 크롤링 정책에 맞게 접근하기 위해 브라우저처럼 보이도록 설정하는 값
.get();
log.info("크롤링 데이터 : {}", document);
} catch (IOException e) {
log.error("크롤링 중 오류 발생", e);
throw new RuntimeException(e);
}
}
}크롤링의 첫 번째 단계로 `Jsoup.connect(url).get()`을 사용해 해당 URL의 정적 페이지를 Document 객체로 가져옵니다.
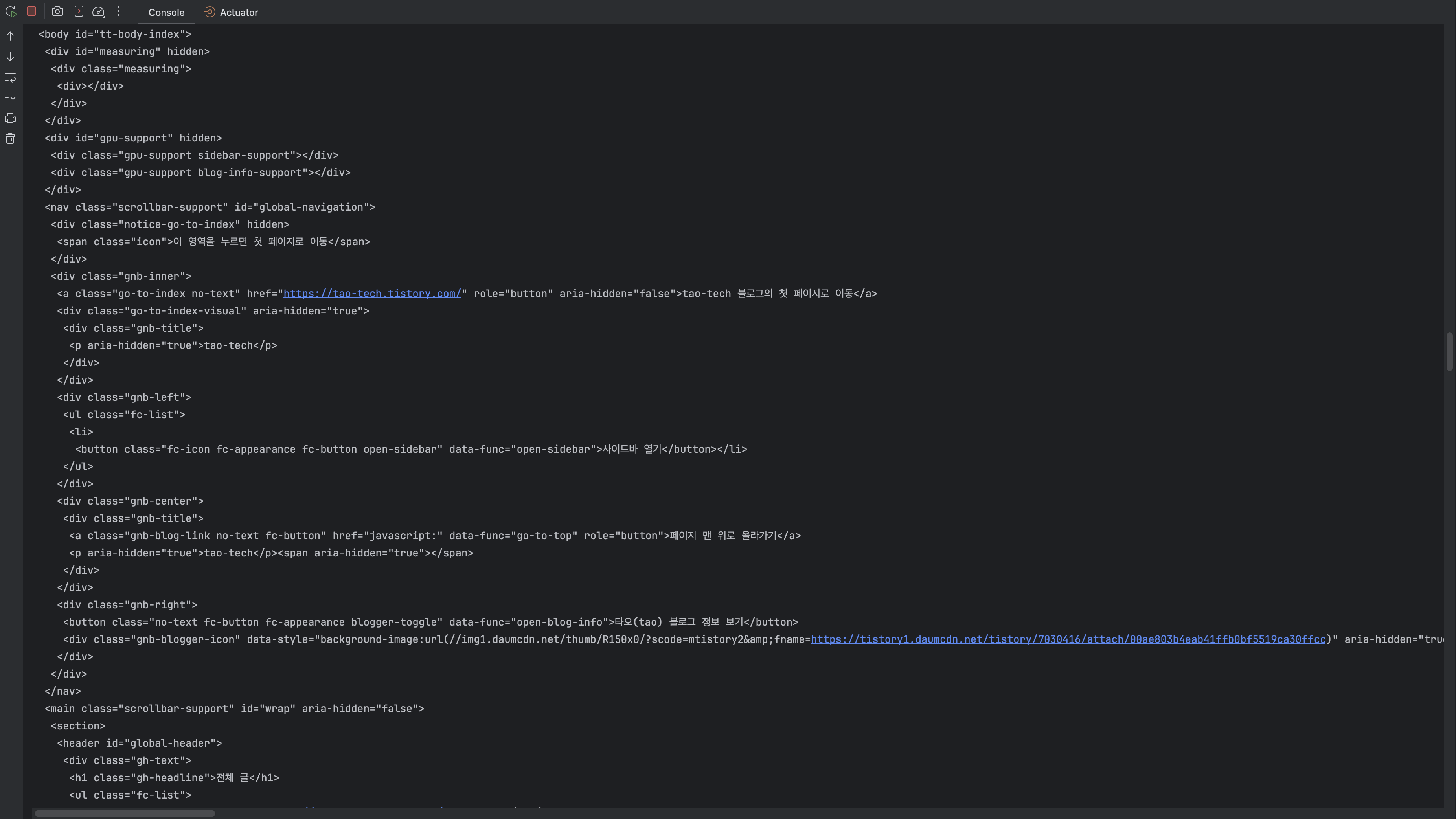

해당 로직을 실행하면 Jsoup을 사용해 connect 한 주소의 document가 생성되는데 이는 해당 사이트에서 정적으로 응답되는 페이지와 같은 것을 알 수 있습니다.
3. Jsoup 크롤링 두 번째 : 데이터 수집
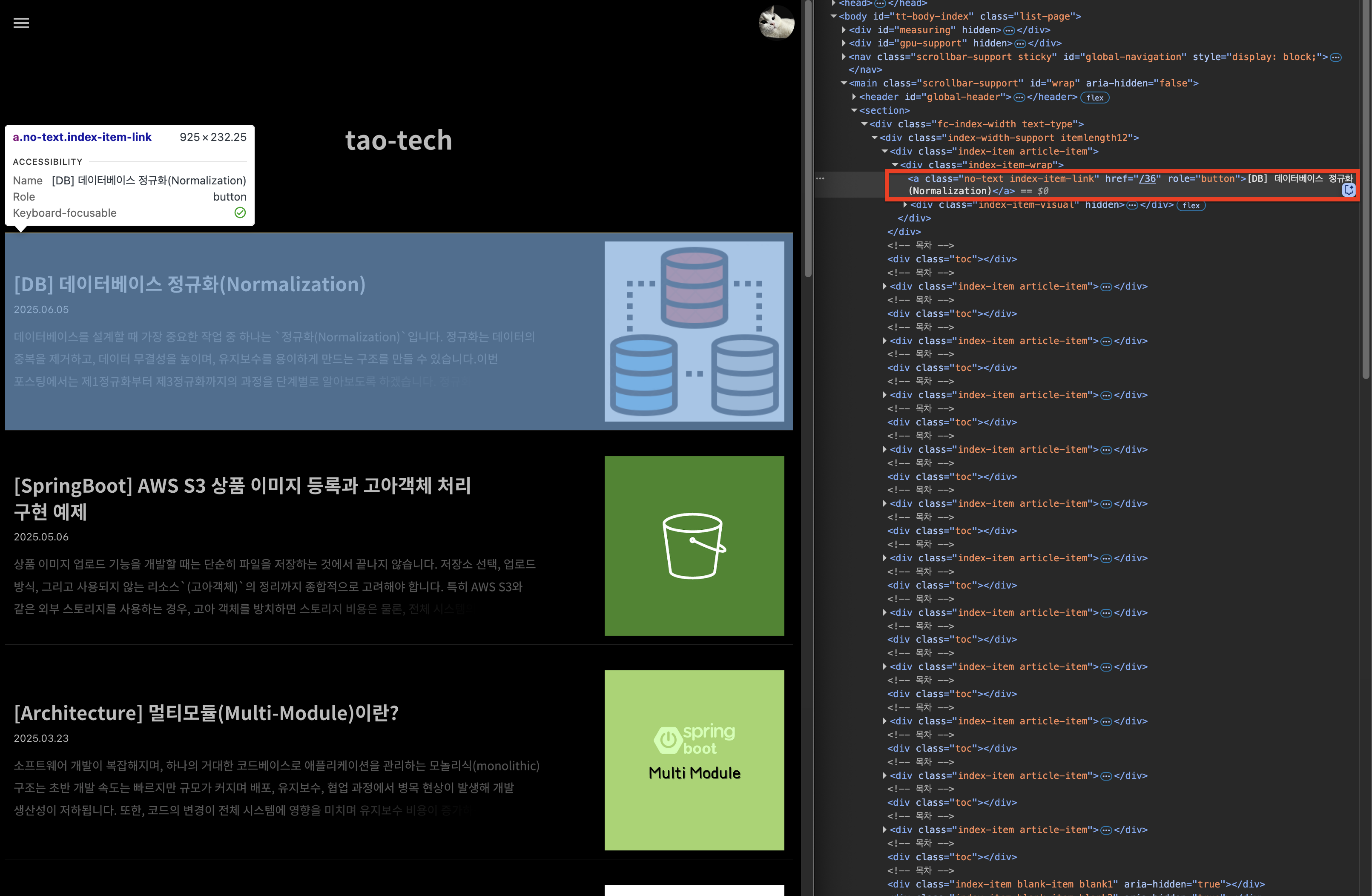
예제에서 크롤링 할 데이터는 `게시글의 제목과 href(url)`입니다.
해당 요소를 찾기 위해 개발자 도구를 열고 Elements 패널에서 해당 요소를 탐색합니다. `윈도우 Control+Shift+S, 맥 Commend+Shift+S`
크롤링 시 HTML 구조의 규칙을 파악하기 위해, 원하는 요소가 어떤 태그와 클래스에 포함되어 있는지 확인하는 것이 중요합니다.
@Slf4j
@Service
public class JsoupCrawler {
private static final String URL = "https://tao-tech.tistory.com";
public List<String> process() {
Document document = null;
try {
document = Jsoup.connect(URL)
.userAgent("Mozilla/5.0") // 크롤링 정책에 맞게 접근하기 위해 브라우저처럼 보이도록 설정하는 값
.get();
return getDataList(document);
} catch (IOException e) {
log.error("크롤링 중 오류 발생", e);
throw new RuntimeException(e);
}
}
private List<String> getDataList(Document document) {
List<String> dataList = new ArrayList<>();
// 실제 글 제목과 링크가 들어있는 요소
Elements elements = document.select("a.index-item-link");
// 지정한 요소를 순회하며 title과 link를 수집
for (Element element : elements) {
String title = element.text();
String link = element.attr("href");
dataList.add(title + " : " + URL + link);
}
return dataList;
}
}HTML 구조를 확인한 결과, 각 게시글에는 `index-item-link` 클래스를 가진 `<a>`태그가 포함되어 있음을 알 수 있었고, 선택자 규칙을 최소화하고 명확하게 하기 위해 `a.index-item-link`를 사용해 Document에서 해당 요소들을 선택하도록 하였습니다.
조회된 요소들을 순회하며 각 요소의 텍스트(제목)와 링크를 추출해 리스트에 추가하였습니다.

위 로직을 실행하면, 블로그의 게시글 제목과 해당 URL이 정상적으로 출력되는 것을 확인할 수 있습니다.
Selenium 이란?
Selenium은 웹 애플리케이션의 테스트 자동화를 위해 개발된 오픈 소스 도구입니다.
웹 브라우저를 실제로 실행하고 조작할 수 있는 기능을 제공하여, 사용자가 마우스 클릭, 키보드 입력, 스크롤 등으로 수행하는 작업을 프로그래밍적으로 자동화할 수 있습니다.
이러한 특성 덕분에 Selenium은 단순한 테스트 도구를 넘어, JavaScript로 동적 렌더링되는 콘텐츠를 수집해야하는 웹 크롤링 용도로도 널리 사용되고 있습니다.
Selenium의 특징
- `동적 콘텐츠 처리 가능` JavaScript로 렌더링되는 웹사이트의 데이터를 가져올 수 있어, `CSR(Client Side Rendering)기반의 사이트에 적합`합니다.
- `실제 브라우저 조작` Chrome, Firefox 등 실제 브라우저를 띄워 동작하며, 사용자와 동일한 환경에서 데이터를 수집합니다.
- `사용자 인터렉션 자동화` 클릭, 드래그, 입력, 스크롤, 이동 등 사용자가 수행하는 거의 모든 행위를 자동화할 수 있습니다.
- `크로스 브라우저 테스트 가능` 여러 브라우저에 대한 호환성 테스트도 가능하여, 테스트 자동화 도구로도 강력한 성능을 발휘합니다.
- `다양한 언어 지원` Java, Python, JavaScript, C#, Ruby 등 여러 언어에서 사용할 수 있는 클라이언트 라이브러리를 제공합니다.
Selenium 사용 예제
Selenium은 Jsoup으로는 불가능한 JavaScript 기반의 동적 콘텐츠 처리가 가능하다는 장점이 있습니다. 이번 예제에서는 필자 블로그에서 특정 카테고리`Spring`의 전체 게시글 제목과 URL을 동적으로 클릭 및 스크롤 처리하여 수집하는 예제를 구성하였습니다.
예제를 크게 세 부분으로 나누어 알아보도록 하겠습니다.
- Selenium 환경 구성 및 페이지 접근 확인
- 동적 요소 제어
- 데이터 수집
부분별로 살펴본 뒤, 마지막으로 전체 코드를 정리해 알아보도록 하겠습니다.
1. 의존성 추가
implementation 'org.seleniumhq.selenium:selenium-java:4.34.0'
implementation 'io.github.bonigarcia:webdrivermanager:5.8.0'- selenium-java
- Selenium 사용을 위한 의존성입니다. 버전확인
- webdrivermanager
- 브라우저 드라이버(ChromeDriver)를 자동으로 다운로드, 설치, 업데이트, 캐시 관리하는 의존성입니다. 버전확인
2. 사전 준비 사항
Selenium은 실제 브라우저를 실행시키기 때문에 몇 가지 사전 조건이 필요합니다.
- 로컬에 브라우저 설치
- 크롬 웹 브라우저 설치하기
- Selenium은 실제 설치된 브라우저를 제어하기 때문에 Chrome, Firefox 등 사용하고자 하는 브라우저가 반드시 PC에 설치되어 있어야합니다. 만약 브라우저가 존재하지 않는다면 Selenium사용 시 에러가 발생합니다.
- 버전 호환성
- WebDriverManager가 브라우저 버전에 맞는 드라이버를 자동 매칭합니다.
- 디스플레이 환경
- Selenium은 실제 브라우저를 실행하기 때문에, GUI가 없는 서버에서는 브라우저를 띄우는 것이 불가능합니다. 이런 경우에는 `--headless` 옵션을 통해 브라우저를 화면 없이 백그라운드에서 실행해야 정상적으로 작동합니다.
3. WebDriver 캐시 위치 및 관리
WebDriverManager는 현재 설치된 브라우저 버전을 감지한 후, 해당 버전에 맞는 드라이버를 원격 저장소에서 다운로드합니다. 다운로드된 드라이버는 사용자 PC에 캐시되어 이후 실행 시 재다운로드하지 않고 재사용됩니다.
- 캐시 저장 위치
- Windows: `C:\Users\<사용자명>\.m2\...` 또는 `C:\Users\<사용자명>\.cache\...`
- Mac: `/Users/<사용자명>/.m2/...` 또는 `/Users/<사용자명>/.cache/...`
- 캐시 제거 방법
- 직접 해당 경로로 이동해 드라이버 파일을 삭제하면 다음 실행 시 다시 다운로드됩니다.
- WebDriverManager 자체에는 코드로 캐시를 강제로 지우는 기능은 따로 없으며, 수동으로 삭제해야합니다.
- 사용자가 직접 캐시 폴더를 삭제하지 않는 이상 재부팅이나 시스템 재시작 후에도 캐시는 유지됩니다.
4. Selenium 크롤링 첫 번째 : 환경 구성
@Slf4j
@Service
public class SeleniumCrawler {
private static final String URL = "https://tao-tech.tistory.com";
public void process() {
// 1. 크롬 드라이버 설치 : 현재 PC에 설치된 크롬 브라우저 버전에 맞는 드라이버 자동 다운로드 및 세팅
WebDriverManager.chromedriver().setup();
// 2. 크롬 옵션 설정 : --headless 설정 시 브라우저 UI 없이 백그라운드 실행
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
// 3. WebDriver 인스턴스 생성 : ChromeDriver는 실제 크롬 브라우저를 제어하는 역할
WebDriver webDriver = new ChromeDriver(chromeOptions);
// 4. 페이지 로딩 대기 설정
WebDriverWait webDriverWait = new WebDriverWait(webDriver, Duration.ofSeconds(5));
try {
// 5. 지정한 URL로 이동
webDriver.get(URL);
// 6. 페이지 로딩 대기 (body 로딩까지 대기)
webDriverWait.until(ExpectedConditions.presenceOfElementLocated(By.tagName("body")));
log.info("접속 완료 : {}", URL);
// 7. 현재 렌더링된 페이지의 HTML 소스를 문자열로 가져오기 : 확인용
String pageSource = webDriver.getPageSource();
log.info("크롤링된 HTML: {}", pageSource);
} catch (Exception e) {
log.error("크롤링 중 오류 발생 : {}", e.getMessage());
throw new RuntimeException(e);
} finally {
// 8. WebDriver 종료 및 리소스 해제 : 생략 시 메모리 누수 발생 가능
webDriver.quit();
}
}
}크롤링 첫 번째 단계로 UI없는 서버 기준 `--headless` 옵션을 설정하고 지정한 URL에 접근합니다. 올바르게 접근하였는지 확인해보기 위해 `getPageSource`로 HTML을 문자열로 출력해보았습니다.
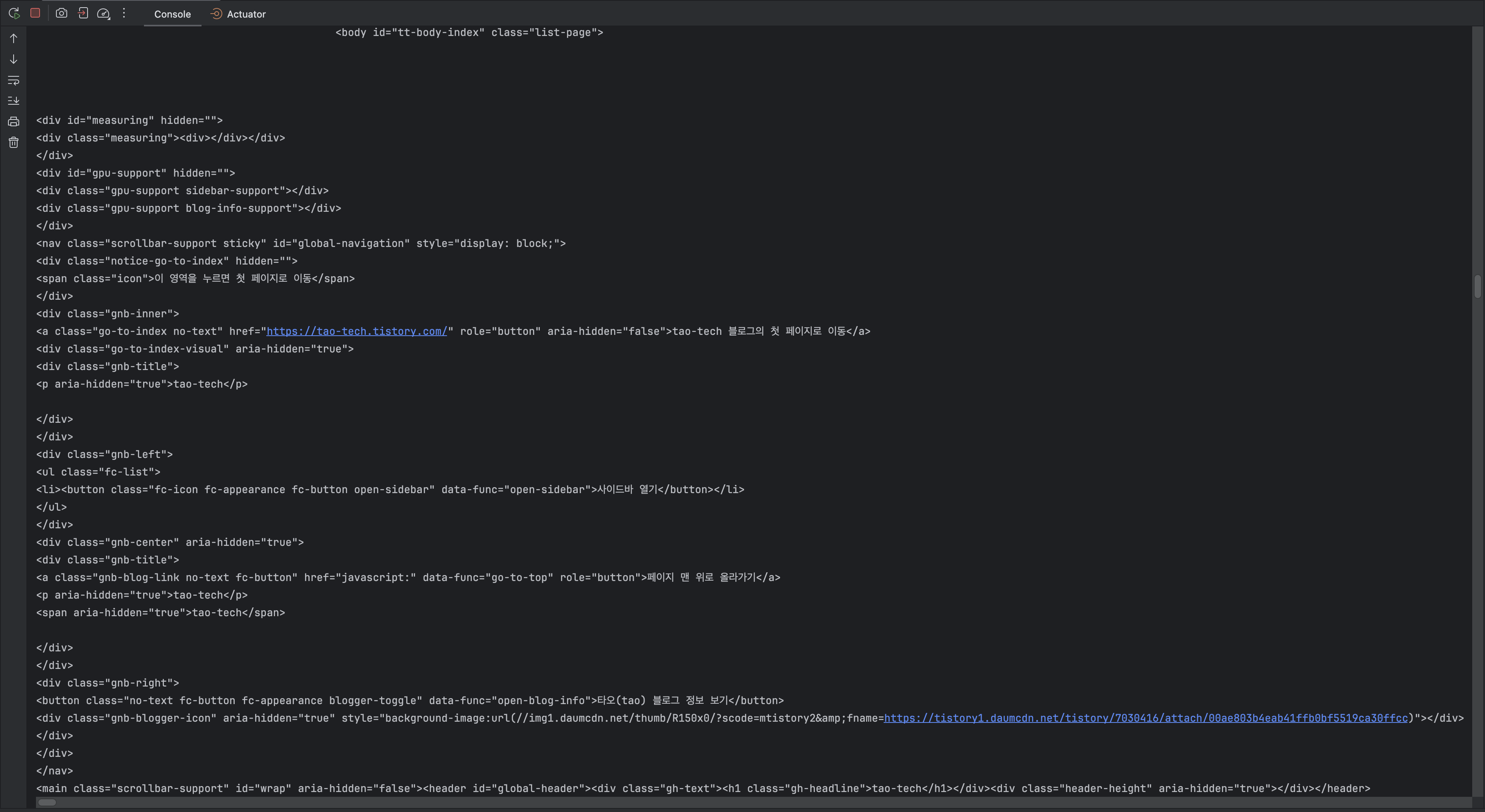
출력된 HTML 문자열을 확인해보면 Jsoup으로 크롤링했을때와 마찬가지로 정상적으로 필자의 블로그 메인페이지 데이터가 출력되는 것을 확인할 수 있습니다.
5. Selenium 크롤링 두 번째 : 동적 제어
앞서 Selenium으로 웹 페이지에 진입하고 HTML을 가져오는 기본 구조를 확인했습니다.
이번 단계에서는 정적 URL을 직접 접근하는 것이 아닌, 실제 사용자가 웹사이트를 탐색하는 것처럼 메인 페이지에서 카테고리 메뉴를 클릭해 Spring 게시글 목록으로 이동해보겠습니다.
이 과정은 Jsoup으로는 불가능한 `동적 DOM 제어` 기능으로, Selenium만의 강점입니다.


먼저 동적요소로 선택 하기위해 블로그의 사이드바를 선택하여 열고 카테고리 리스트를 탐색하였습니다.
먼저 사이드바를 열기위해 탐색한 요소로 `By.cssSelector("button[data-func='open-sidebar']")`를 클릭하여 사이드바를 열고 카테고리 요소인 `By.cssSelector(".category_list a.link_item")`을 사용하여 해당 카테고리를 클릭해 해당 카테고리로 접속하도록 하겠습니다.
@Slf4j
@Service
public class SeleniumCrawler {
private void clickCategory(WebDriver webDriver, WebDriverWait wait, String category) {
try {
// 1. 사이드바 열기 버튼이 존재하면 클릭
List<WebElement> sidebarButtons = webDriver.findElements(By.cssSelector("button[data-func='open-sidebar']"));
if (!sidebarButtons.isEmpty()) {
WebElement sidebarButton = sidebarButtons.getFirst();
if (sidebarButton.isDisplayed() && sidebarButton.isEnabled()) {
sidebarButton.click();
log.info("사이드바 열기 버튼 클릭");
}
}
// 2. 지정된 카테고리 항목이 존재할 때까지 대기
wait.until(driver -> {
List<WebElement> elements = driver.findElements(By.cssSelector(".category_list a.link_item"));
return elements.stream().anyMatch(e -> !e.getText().trim().isEmpty());
});
// 3. 텍스트 비교 후 원하는 카테고리 클릭
List<WebElement> categories = webDriver.findElements(By.cssSelector(".category_list a.link_item"));
for (WebElement element : categories) {
String text = element.getText().trim();
log.info("카테고리 항목: {}", text);
if (text.startsWith(category)) {
element.click();
log.info("카테고리 클릭 성공: {}", category);
return;
}
}
throw new IllegalStateException("해당 카테고리를 찾지 못했습니다: " + category);
} catch (Exception e) {
log.error("{} 카테고리 클릭 실패: {}", category, e.toString());
throw new RuntimeException(e);
}
}
}주석으로 동작흐름에 대해 설명을 남겨놓았습니다.
해당 로직을 기존 호출로직에서 다음과 같이 호출합니다. `(웹드라이버, 대기 설정, 카테고리 지정)`
clickCategory(webDriver, webDriverWait, "Spring");

실행 결과, 원하는 카테고리를 찾아 클릭하는 과정이 정상적으로 동작하는 것을 확인할 수 있습니다.
6. Selenium 크롤링 세 번째 : 데이터 수집
앞서 Selenium을 이용해 Spring 카테고리로 정상적으로 이동한 것을 확인했습니다.
이번 단계에서는 해당 카테고리 페이지에서 실제 게시글 제목과 URL을 수집해보도록 하겠습니다. 게시글 목록은 Jsoup 사용시와 마찬가지로 HTML 상에서 `<a class="index-item-link">` 형태로 구성되어 있어, 이를 선택자로 활용할 수 있습니다.
@Slf4j
@Service
public class SeleniumCrawler {
private List<String> getDataList(WebDriver webDriver) {
List<String> dataList = new ArrayList<>();
// 게시글 링크 요소 선택
List<WebElement> postElements = webDriver.findElements(By.cssSelector("a.index-item-link"));
for (WebElement element : postElements) {
String title = element.getText().trim();
String link = Objects.requireNonNull(element.getAttribute("href")).trim();
dataList.add(title + " : " + link);
}
return dataList;
}
}위 코드에서 사용된 `index-item-link` 클래스는 티스토리에서 각 게시글을 감싸고 있는 `<a>` 태그의 클래스입니다. Selenium을 통해 해당 요소들을 모두 수집하고, 각각의 제목과 링크를 추출하여 리스트로 반환합니다.
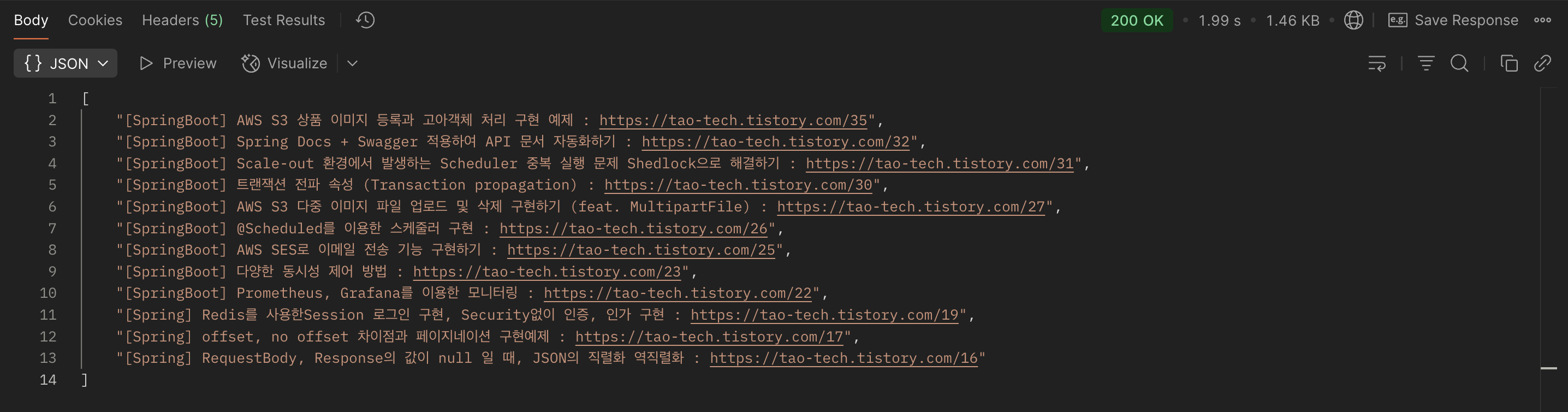
해당 로직 실행 시 정상적으로 Spring 카테고리에만 있는 게시글 데이터를 확인할 수 있습니다.
7. Selenium 크롤링 전체 코드
@Slf4j
@Service
public class SeleniumCrawler {
private static final String URL = "https://tao-tech.tistory.com";
public List<String> process() {
// 1. 크롬 드라이버 설치 : 현재 PC에 설치된 크롬 브라우저 버전에 맞는 드라이버 자동 다운로드 및 세팅
WebDriverManager.chromedriver().setup();
// 2. 크롬 옵션 설정 : --headless 설정 시 브라우저 UI 없이 백그라운드 실행
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
// 3. WebDriver 인스턴스 생성 : ChromeDriver는 실제 크롬 브라우저를 제어하는 역할
WebDriver webDriver = new ChromeDriver(chromeOptions);
// 4. 페이지 로딩 대기 설정
WebDriverWait webDriverWait = new WebDriverWait(webDriver, Duration.ofSeconds(5));
try {
// 5. 지정한 URL로 이동
webDriver.get(URL);
// 6. 페이지 로딩 대기 (body 로딩까지 대기)
webDriverWait.until(ExpectedConditions.presenceOfElementLocated(By.tagName("body")));
log.info("접속 완료 : {}", URL);
// 7. Spring 카테고리 클릭
clickCategory(webDriver, webDriverWait, "Spring");
// 8. 데이터 수집 후 결과 리턴
return getDataList(webDriver);
} catch (Exception e) {
log.error("크롤링 중 오류 발생 : {}", e.getMessage());
throw new RuntimeException(e);
} finally {
// 9. WebDriver 종료 및 리소스 해제 : 생략 시 메모리 누수 발생 가능
webDriver.quit();
}
}
private void clickCategory(WebDriver webDriver, WebDriverWait wait, String category) {
try {
// 7-1. 사이드바 열기 버튼이 존재하면 클릭
List<WebElement> sidebarButtons = webDriver.findElements(By.cssSelector("button[data-func='open-sidebar']"));
if (!sidebarButtons.isEmpty()) {
WebElement sidebarButton = sidebarButtons.getFirst();
if (sidebarButton.isDisplayed() && sidebarButton.isEnabled()) {
sidebarButton.click();
log.info("사이드바 열기 버튼 클릭");
}
}
// 7-2. 지정된 카테고리 항목이 존재할 때까지 대기
wait.until(driver -> {
List<WebElement> elements = driver.findElements(By.cssSelector(".category_list a.link_item"));
return elements.stream().anyMatch(e -> !e.getText().trim().isEmpty());
});
// 7-3. 텍스트 비교 후 원하는 카테고리 클릭
List<WebElement> categories = webDriver.findElements(By.cssSelector(".category_list a.link_item"));
for (WebElement element : categories) {
String text = element.getText().trim();
log.info("카테고리 항목: {}", text);
if (text.startsWith(category)) {
element.click();
log.info("카테고리 클릭 성공: {}", category);
return;
}
}
throw new IllegalStateException("해당 카테고리를 찾지 못했습니다: " + category);
} catch (Exception e) {
log.error("{} 카테고리 클릭 실패: {}", category, e.toString());
throw new RuntimeException(e);
}
}
private List<String> getDataList(WebDriver webDriver) {
List<String> dataList = new ArrayList<>();
// 8-1. 게시글 링크 요소 선택
List<WebElement> postElements = webDriver.findElements(By.cssSelector("a.index-item-link"));
// 8-2. 지정한 요소를 순회하며 title과 link를 수집
for (WebElement element : postElements) {
String title = element.getText().trim();
String link = Objects.requireNonNull(element.getAttribute("href")).trim();
dataList.add(title + " : " + link);
}
return dataList;
}
}
부분별로 살펴본 Selenium을 이용한 크롤링 전체 코드를 정리하여 주석으로 설명을 남겨놓았으니 참고바랍니다.
티스토리 블로그의 경우 정적페이지로, Jsoup을 사용해서도 URL을 코드내에서 동적으로 설계하여 Selenium으로 구현한 크롤링과 동일하게 구현이 가능하나, Jsoup에서는 불가능한 동적제어를 보여주기 위해 URL은 고정한 상태로 실제 버튼들을 클릭하여 동작하는 예제를 구성하였습니다. Selenium은 이러한 동적제어를 통해 `CSR(Client Side Rendering)` 방식의 페이지에서도 크롤링이 가능합니다.
Jsoup과 Selenium의 차이점 정리
| 항목 | Jsoup | Selenium |
| 동작 방식 | HTML 문서를 직접 파싱 (정적 HTML 기반) | 실제 브라우저를 제어 (동적 JavaScript 처리 가능) |
| JavaScript 처리 | ❌ 불가능 (렌더링 전 HTML만 접근) | ✅ 가능 (실제 렌더링된 DOM 제어 가능) |
| 속도 | 매우 빠름 (HTTP 요청 + 파싱) | 느림 (브라우저 구동 + 렌더링 시간 포함) |
| 환경 요구사항 | 별도 설치 없이 동작 | 브라우저 설치 + WebDriver 세팅 필요 |
| 사용 난이도 | 간단한 API, 상대적으로 학습 쉬움 | 브라우저 제어 로직 필요, 상대적으로 복잡 |
| 사용 목적 | 정적 페이지 크롤링, 간단한 파싱 | 동적 페이지 크롤링, 사용자 이벤트 시뮬레이션 |
| 스크롤, 클릭 등 UI 조작 | ❌ 불가능 | ✅ 가능 (클릭, 입력, 스크롤 등 모두 지원) |
| 테스트 자동화 용도 | ❌ 사용하지 않음 | ✅ 웹 UI 테스트 자동화용으로도 사용 |
| 라이브러리 크기, 의존성 | 가볍고 단일 JAR로 가능 | 무거움 (드라이버, 브라우저 필요) |
- Jsoup은 상대적으로 학습비용이 적고 빠르게 정적 페이지를 크롤링하는데 용이합니다.
- Selenium은 상대적으로 학습비용이 높고 무겁지만 웹 UI 테스트 자동화, 클릭, 입력, 스크롤 등을 사용하여 동적으로 페이지 크롤링이 가능합니다.
이러한 특성으로 Selenium으로 동적 페이지를 탐색하여 pageResource를 생성하여 Jsoup으로 데이터를 수집하는 등 `Selenium + Jsoup` 조합하여 효율적인 크롤링 또한 가능합니다.
// Selenium으로 렌더링된 HTML 가져오기
String renderedHtml = webDriver.getPageSource();
// Jsoup으로 파싱하여 원하는 데이터 수집
Document doc = Jsoup.parse(renderedHtml);
Elements posts = doc.select("a.index-item-link");이러한 조합 방식은 `렌더링은 Selenium, 파싱은 Jsoup`이라는 각자의 장점을 살리는 구조로, 복잡한 페이지 크롤링 작업에서 효율성과 성능을 동시에 확보할 수 있습니다.
마무리
웹 크롤링은 단순한 데이터 수집을 넘어, 정보 분석과 자동화의 핵심 기술입니다. Java 환경에서는 Jsoup과 Selenium이라는 도구들이 각각의 특성과 용도에 따라 적절히 활용될 수 있습니다.
정적인 페이지에서는 가볍고 빠른 Jsoup을, 동적인 JavaScript 기반 페이지나 사용자 액션이 필요한 환경에서는 Selenium을 사용합니다.
특히, 복잡한 크롤링 시에는 Selenium으로 페이지를 탐색하고 Jsoup으로 데이터를 정제하는 방식도 고려해볼 수 있습니다. 중요한 것은 도구 그 자체가 아니라, 크롤링의 목적과 환경에 따라 가장 적합한 도구를 선택하는 것입니다.
'Java' 카테고리의 다른 글
| [Java] Stream이란? 사용하는 이유와 활용 방법 (0) | 2025.03.04 |
|---|---|
| Entity에 Setter사용을 지양하는 이유 feat.DTO, Entity 간 변환 (0) | 2024.09.26 |
| Java - Scanner 클래스 next(), nextLine()의 차이 (0) | 2024.05.27 |